
Welcome back everyone 👋 and a heartfelt thank you to all new subscribers who joined in the past week!
This is the 72nd issue of the Gorilla Newsletter - a weekly online publication that sums up everything noteworthy from the past week in generative art, creative coding, tech, and AI.
If it's your first time here, we've also got a discord server now, where we nerd out about all sorts of genart and tech things - if you want to connect with other readers of the newsletter, come and say hi: here's an invite link!
That said, hope that you're all having an awesome start into the new week! Here's your weekly roundup 👇
All the Generative Things
Le Random Completes their Genart Timeline
Last Monday, September 2nd, marked the completion of Le Random's expansive generative art timeline. After nearly two years in the making, the massive documentation project catches up to the present day, and in over a 1000 distinct moments it captures all important and influential instances that contributed to the evolution of generative art as we know it today. You can explore the timeline for yourself here:

The final 10th chapter focuses on the most recent history of generative art - technically only the first half of the current decade - but arguably the most transformative and explosive era that really accelerated the global discourse around the artform, particularly in context of blockchain technology that has opened many new avenues for code as an artistic medium.
As per usual, the release of each chapter is commemorated with a panel that features the most influential characters of the era, and this time is no different, in their podcast Le Random invites Lauren Lee McCarthy, Erick Calderon, Itzel Yard, Rafael Lozano-Hemmer:
Monk explains that this should not be considered the end of the timeline though, but rather as a big milestone in Le Random's efforts. The team will continue to refine the content of the timeline, with a planned UI overhaul to make things more user-friendly. It's also revealed that a book is in the making - which I must say, is something that I'm quite excited for.
Computational Life: Self-Replicating Programs
A recent research paper from the Google Paradigms of Intelligence Team shows that a primordial soup of randomly stringed together characters using the esoteric Brainfuck programming language gives rise to self-replicating machines (programs):
Released back in June of this year it's not an entirely new paper, but I only just found the time to look into it - it's arguably one of the most interesting computational experiments that I've read about this year.
Artificial life has been a topic of research for many decades now; with John von Neumann being recognized as a pioneering researcher of the field in the 1940s. He was the first to propose a formal model of a self-replicating machine - a device that when run, could create a copy of itself. To describe this machine in more detail von Neumann simultaneously laid the groundwork for what we know today as Cellular Automata, later even leading to Conway defining the famous Game of Life.
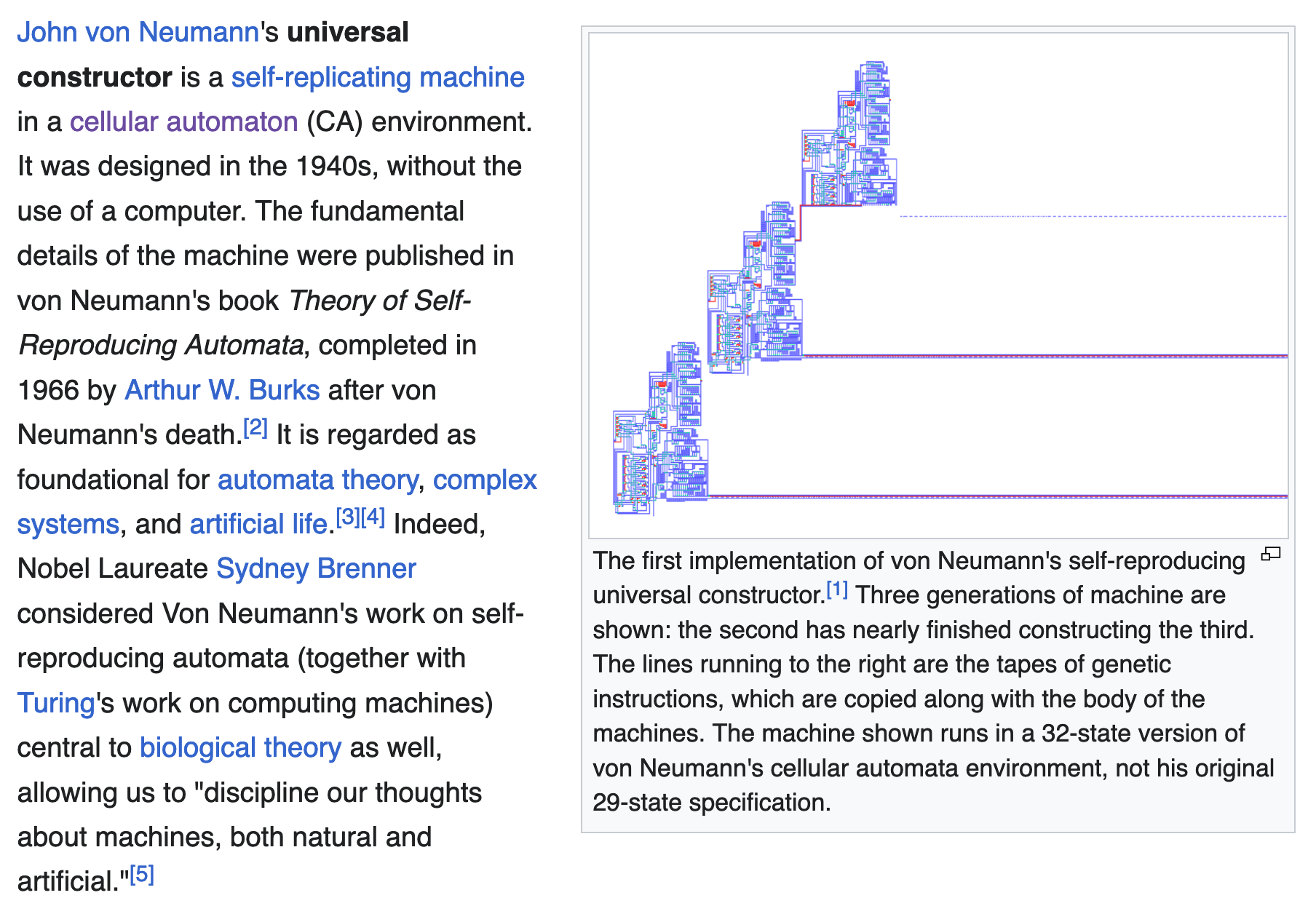
Even if a cellular automaton may seem simplistic in its nature when compared to the complexity of real life, they're still in many ways revelatory about the mechanisms of entropy and emergence. In the Google research paper this topic is explored by creating an artificial setting in which self-replicating machines can emerge by themself without any man-made precedent. The creative twist here is that this is achieved by leveraging the Brainfuck programming language.
If you've never heard of it, Brainfuck is an esoteric programming language created in 1993 by Urban Müller, that is widely known today for its obscure minimalism. The language features only eight commands (>, <, +, -, ., ,, [, and ]) and operates by manipulating an array of memory cells, that is initialized to zero. A memory pointer is used to move left or right, and increment or decrement the value at the current cell, and even input or output data. Loops are also possible and controlled using brackets ([ and ]). All of this allows for complex behavior despite the simplicity of the command set, for instance, the "Hello World" program in Brainfuck would look as follows:
>++++++++[<+++++++++>-]<.>++++[<+++++++>-]<+.+++++++..+++.>>++++++[<+++++++>-]<++.------------.>++++++[<+++++++++>-]<+.<.+++.------.--------.>>>++++[<++++++++>-]<+.Conveniently this means that any random collection of these symbols makes for a valid program. While the language is Turing-complete (meaning that you can theoretically perform any type of computation with it), using it in any kind of practical setting is virtually impossible due to its low-level and highly abstract nature.
In the paper a modified version of the language (referred to as BFF) is used, where data and instructions share the same tape - such that both the program's code (the instructions basically) and the data it manipulates are stored in the same memory space, meaning that the system can alter its own code as it is running, allowing for self-modification. The paper describes a larger system that is made out of many small programs (64 bytes long) containing random instructions from a simple set of operations. These programs are placed in a "soup" where they interact, concatenate, and execute each other’s code - the underlining point being that this is happening entirely at random.
While the expectation here is that the primordial soup will simply do nothing, as it has no incentive to do anything, the surprising observation is that after a while self-replicating programs start to emerge slowly overtaking the entire system. And this despite specifying any explicit fitness landscape, guiding selection pressures, or external incentives, but merely through random interactions and self-modifications. In this setting a self-replicator can be defined as a program who's self-modifying operations happen to copy itself (or part of itself) accurately, allowing it to spread to other regions of the soup - leading to a more complex dynamic where the replicators compete for space and resources. In the paper this is likened to autocatalytic chemical reactions.
That's as far as I understand it - I might be getting some things mixed up however. A great video that explains the paper in simple terms is from Anton Petroc, which also shows some visualizations of the primordial soup and the behavior it exhibits when it gets overtaken by a self-replicating mechanism:
One of the comments left on the video was also quite intriguing and worth including here:

The Art of Finishing by Tomas Stropus
Starting a new project is always infinitely easier than getting back into a half-baked thing that's been gathering dust for a while. In many ways it's a cognitive and emotional challenge: picking up the mental state that you were in, back when a particular project was first coming together, is not an easy feat to achieve, as the initial driving motivations might have waned, or because you might have moved on to other ideas in the meantime. And that's besides the technical debt and unresolved issues that the project was left off with.
While determination can go a long way in this kind of scenario - à la "I won't get up from my desk until it's done" - it's better to actually have a meaningful gameplan. Tomas Stropus talks about this in an article of his titled "The Art of Finishing" - although the article isn't really about generative art in particular, I believe that it's applicable to all sorts of creative endeavors and a universal feeling shared by many artists, makers and creatives. Tomas first identifies some of the reasons why we get stuck in this kind of "never finishing anything loop" and then enumerates some strategies to remedy the problem:
 Tomas Stropus
Tomas Stropus
One paragraph in particular struck a chord, it's something I've felt at many points throughout my creative endeavors - an accumulating feeling of not being able to get anything done at all:
The costs of never finishing extend far beyond just missed opportunities. [...] it’s in the act of finishing — of solving those last, trickiest problems — where real skill growth often occurs. Each unfinished project can chip away at your confidence.
The most noticeable personal growth I've experienced was from finally releasing my projects out into the world - it's difficult to describe, but you always see the project in a different perspective afterwards.
Maybe one of the best tips he gives throughout is "separating ideation from implementation" which is something that I've personally also been trying to adopt; basically allocating time for meaningful progress driven work "implementation", and some time for messing around "ideation". In a practice like generative art, or even web design, it's easy to lose yourself in the details, and start fine-tuning things when there's more pressing things to work on first. I assume that my ADHD brain is probably particularly prone to this, but it's simply a really bad habit that creeps back in sometimes and can cause a lot of time loss.
Other Cool Generative Things
- Alexandre Villares has been making one sketch a day since 2018 - and he's documented all of it over on his website, where you can explore the entire archive and even find code for each individual sketch.
- The second installment of the Responsive Dreams generative art festival took place last week in Barcelona (5th to 7th), featuring many familiar faces of the genart crowd that had their works on display. You can learn more about it over on the official website.
- Next week, in another part of Spain, Digital Art Day Málaga 2024 is taking place, a conference celebrating not only generative art, but digital art in general. Another group of established generative artists will by making an appearance, and I'm hoping that the presented talks will be recorded in some manner.
- Pikuma shares an open source, bare metal, raycaster written in x86 assembly - that boots from a floppy disk and doesn't require an OS to run. Made by Stillwwater.
- Pulsar is a tiny creative coding website that lets you explore grid SDFs by writing a mathematical formula to control the visualized animation.
Tech & Web Dev
TC39 Introduces New Stage into Feature Pipeline
The TC39 committee that's in charge of developing the ECMAScript specification language recently introduced a new stage into their 5 step feature development pipeline, namely stage 2.7. It finds itself between the Draft and Candidate stage, and addresses the challenge of ensuring that proposals are thoroughly tested before implementation in browsers and runtimes:

Previously, proposals sometimes had to revert to earlier stages when design changes necessitated rewriting tests, resulting in wasted effort. Stage 2.7 is now a marker that a feature's design is stable and requires only testing and validation before moving to full implementation in Stage 3 — this separation allows for smoother transitions and reduces redundant work, particularly for large or complex proposals like ShadowRealm. Here the numbering was carefully chosen to reflect the position of the stage in the pipeline.
The Fastest JS Color Library
You might remember romgrk from issue #50 of the newsletter, where we had a look at their insightful article on various methods for optimizing JavaScript code. They recently made a return with an article that introduces their very own JS color library called "color-bits" - boldly claiming that it is the fastest JS color manipulation library out there. In the complementary article romgrk explains why this is the case, and in a way also documents the development process of the lib:

romgrk points out a number of inefficiencies in common methods for representing and manipulating RGBA colors, that are commonly stored as objects like {red: 0, green: 0, blue: 0, alpha: 1.0} - while this approach is generally readable, it also results in heavy garbage collection due to object creation. To remedy this, rmgrok suggests encoding RGBA values into a single 32-bit number using bitwise operators, which significantly reduces memory overhead.
After a lengthy exploration of how different JavaScript runtimes deal with 32-bit numbers, romgrk ends up embracing JS's signed number system, recognizing that the underlying bit patterns remain correct for their needs, even if the values are interpreted as negative numbers.
Other Cool Tech Things
- When Regex Goes Wrong is a case study by Trevor Lasn examining a regex backtracking mishap that caused StackOverflow to experience a downtime of 34 minutes in 2016. He also brings up other instances where regex happened to be the critical point of failure.
- Andy Bell is back with yet another article for the Picalilli blog, this time teaching us how to create breakout elements with container queries, which was also a part of the Picalilli redesign.
AI Corner
What's really going on in Machine Learning?
I wasn't aware that Stephen Wolfram, who you might know as the creator of Mathematica and Wolfram|Alpha, was actually publishing writings over on his website - and that fairly regularly (at least once a month or so). Towards the end of August Wolfram published a massive deep dive in which he takes a fascinating reductive approach to explaining the inner workings of neural networks, via his own minimal toy models - and ends up making a deeply interesting observation during the endeavor:

One surprising result is that neural nets can be simplified to a great extent while still retaining a big part of their capabilities - Wolfram makes use of a structurally simpler and discretized type of neural network for this purpose. The other very surprising observation is that models don't actually end up relying on any sort of structured mechanism to achieve the tasks that they're trained on, but rather tap into "the general richness of the computational universe", which sounds a bit esoteric - and I don't fully grasp how that can be - but is in essence related to a Wolfram's previous notion of Computational Irreducibility.
Computational Irreducibility is the idea that some systems, especially those that follow simple rules, can produce behavior so complex that no shortcut or simplified method exists to predict their outcomes. To know the result, you'd have to let the system run its full course, as there’s no faster way to determine what will happen than by performing the actual steps. This suggests that even though the ruleset is simple, the complexity it generates is irreducible and cannot be easily predicted or simplified.
If you only have time for one article this week, this is the one - will most likely give it a couple more reads to fully grasp everything that Wolfram tackles throughout.
Tobias van Schneider on the AI Hype
Another insightful read this week, about the current state of AI, is a think-piece by Tobias van Schneider. He contemplates the rapid rise of AI in recent years and makes a couple of predictions for where he thinks we're headed with the tech:

AI has unarguably catalyzed a moral and technological shift, comparable to that of the industrial revolution – particularly in areas like copyright, intellectual property, and privacy. This shift is also reshaping societal norms and aggravating a growing generational divide on AI acceptance. The most interesting point that Tobias makes however, is his prediction of a counter wave against AI; an eventual turning point in the content creation meta that'll focus on more personalized, human-driven experiences—where craftsmanship and human connection will serve as a response to the hyper-efficient but boring AI content.
Music for Coding
Kikagaku Moyo is japanese and means as much as "Geometric Patterns" - which make the band a no-brain inclusion for the Newsletter, they're a psychedelic band founded in Tokyo in 2012 - unfortunately now on an indefinite hiatus since 2022. Mammatus Clouds is comprised of just 3 songs, with the first takes up more than half of the records' time. Their sound is a mix of atmospheric, tribal sounds with a psychedelic element:
And that's it from me—hope you've enjoyed this week's curated assortment of genart and tech shenanigans!
Now that you find yourself at the end of the Newsletter, you might as well share it with some of your friends - word of mouth is till one of the best ways to support me! Otherwise come and say hi over on my socials - and since we've got also got a discord now, let me shamelessly plug it again here. Come join and say hi!
If you've read this far, thanks a million! If you're still hungry for more generative art things, you can check out last week's issue of the newsletter here:

And a backlog of all previous issues can be found here:

Cheers, happy coding, and again, hope that you have a fantastic week! See you in the next one!
- Gorilla Sun 🌸