Welcome back everyone 👋 and a heartfelt thank you to all new subscribers who joined in the past week!
This is the 79th issue of the Gorilla Newsletter - a weekly online publication that sums up everything noteworthy from the past week in generative art, creative coding, tech, and AI.
If it's your first time here, we've also got a discord server now, where we nerd out about all sorts of genart and tech things - if you want to connect with other readers of the newsletter, come and say hi: here's an invite link!
That said, hope that you're all having an awesome start into the new week! Here's your weekly roundup 👇
All the Generative Things
...and other creatively computational thingamajigs!
On Crafting Painterly Shaders
Developed in 1976 by the Japanese researcher Hiroshi Kuwahara, the Kuwahara filter is an image processing technique that’s primarily used for edge-preserving smoothing and reducing noise while maintaining sharp boundaries in an image. It also turns out to be the secret sauce for painterly shaders—shaders that mimic paint, watercolor, and aquarelle textures when used as a post-processing filter. Maxime Heckel describes how this works in detail with his newest massive deep dive:

The kuwahara filter essentially works by inspecting a square region around each individual pixel, splitting it into four overlapping smaller squares. In each of these squares, the filter calculates the average color and the amount of variation in color. Then, it picks the region with the least variation, meaning it’s the smoothest or most uniform area assigning it to the pixel in the center. This filtering technique has the effect of preserving edges but also manipulates the image in a way that makes it look painterly.
Maxime doesn’t stop at implementing a simple Kuwahara filter however, but also explains further improvements to really take the effect to the next level. One of them is a modification Giuseppe Papari proposed in his 2007 paper Artistic Edge and Corner Enhancing Smoothing, that replaces the square filter with a circular area. I won’t spoil too much more however and leave you to read through the article by yourself.
Djikstra’s Algorithm proven Optimal
TLDR: This past week a new paper from a group of researchers at INSAIT shows that with an elegant modification Djikstra’s shortest path algorithm can become universally optimal!
There’s a bunch of stuff to unpack here: for those that aren't familiar, what actually is Djikstra’s Algorithm and what does it do? What’s the modification this new paper makes? And what does it actually mean for an algorithm to be universally optimal?
The famous shortest-path algorithm can not only be considered as a cornerstone of Djikstra’s fame, but also as a cornerstone of computation itself; it’s become a staple in undergraduate computer science curricula around the world. Unsurprisingly, I learned about it for the first time in my algorithms and data sctructures course, and looking back it was one of the most rewarding and fun materials that we learned about in the course. Years later I rediscovered graph traversal algorithms for generative art purposes—Djikstra’s algo being one of them—here’s two things I made where the algo plays an important role:
As the name suggests, shortest path algorithms are methods for finding the shortest path from a starting node to a target node, usually in a network—a weighted graph—where nodes can be connected in arbitrary mannes. A weighted graph simply means that each edge between two nodes has a numerical value, or "weight," associated with it, representing a cost, distance, or other quantity. In this setting the shortest also means least costly.
Nodes in this setting are usually modeled in an object oriented manner, where each node is its own instance holding references to the nodes it is connected to—basically its neighbors. The graph then emerges in an implicit manner by means of connecting nodes with each other. I won't regurgitate the individual steps of the algorithm here, since there's like a million posts about it, but the Wikipedia page provides a pretty good description.
Edsger Dijkstra came up with his shortest-path algorithm in a surprisingly casual way—in an interview he gave in 2010 towards the end of his life, he gives a beautiful recount of how the idea for the algorithm came to be:
One morning I was shopping in Amsterdam with my young fiancée, and tired, we sat down on the café terrace to drink a cup of coffee and I was just thinking about whether I could do this, and I then designed the algorithm for the shortest path. As I said, it was a 20-minute invention.
He published his idea three years later in 1959 in a paper titled “A Note on Two Problems in Connexion with Graphs”, and after the algorithm gained widespread popularity, a lot of research went into finding optimizations. In 1984 the two scientists Michael Fredman and Robert Tarjan demonstrated that Djikstra’s algorithm can actually be worst-case optimal with a modification, in their paper “Fibonacci Heaps and Their Uses in Improved NetworkOptimization Algorithms".
In this setting Worst-case Optimal means that no algorithm could possibly solve a given problem faster in the most difficult situation. It's like saying "even in the hardest possible case, this is as fast as anyone could ever make it." Fredman and Tarjan showed this for Dijkstra's algorithm by using a clever heap data structure to store and update distances, which they call a Fibonacci heap and describe in an earlier paper of theirs. If you're curious about it, here's a really good explainer by SithDev:
In essence, using a Fibonacci heap improves Dijkstra's algorithm by making it faster to select and update the node with the smallest distance. In steps where Dijkstra’s algorithm finds the closest unvisited node and updates distances to neighboring nodes, a Fibonacci heap handles these tasks more efficiently than a regular heap, and can quickly find the minimum, allowing for fast updates when shorter paths are discovered.
Tarjan continued to make a number of important contributions to graph papers over the years, and his name is also on this newest paper, that goes a step beyond and proves that Djikstra’s algorithm is not only worst-case optimal, but universally optimal. Universally Optimal means that the algorithm is as efficient as possible across all different types of graphs, not just in the worst-case scenarios. I’m not going to claim that I exactly understand how this works—but in essence they use a new smarter version of the Fibonacci heap that adapts based on how the algorithm is accessing nodes, further optimizing these operations. Naturally there's also the mathematical part that proves this claim.
I hope this was relatively informative—the reason I'm writing about the topic is because I came across this article by Ben Brubaker for Quanta Magazine, tackling the very same paper, for which the animation in the banner was made by none other than Dave Whyte aka beesandbombs:
 Ben Brubaker
Ben Brubaker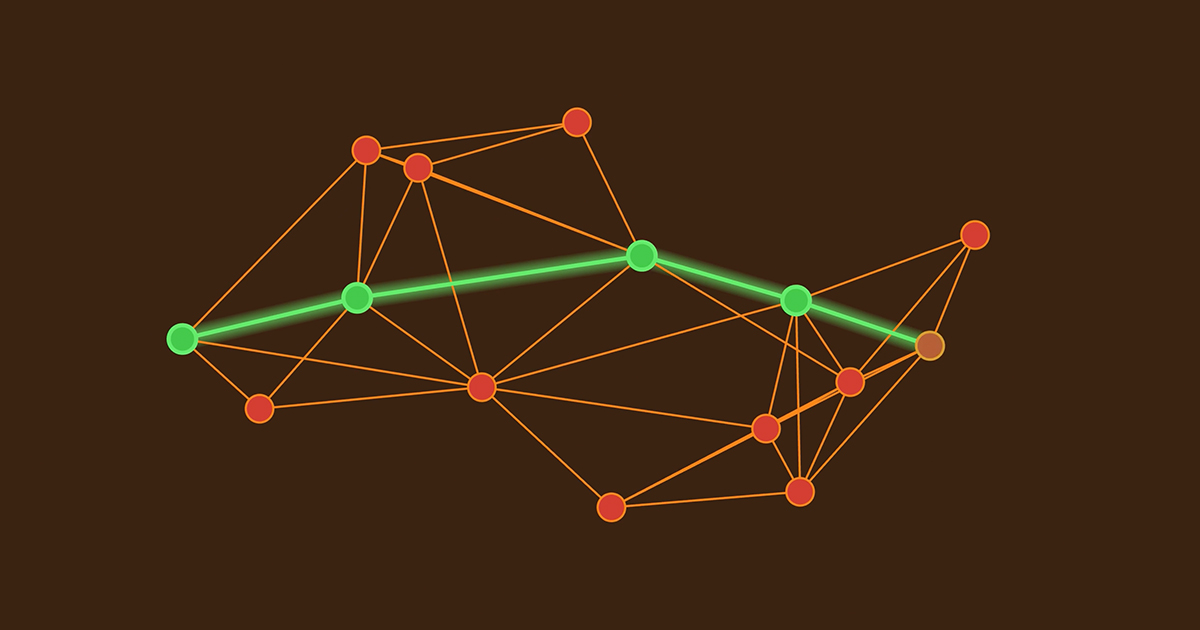
Uniform Point Distribution on an Infinite Grid
Poisson Disk Sampling is a popular technique for generating aesthetically pleasing, seemingly uniform point distributions. In a Poisson Disk Sampling points are distributed on a surface in such a manner that each point is separated from its neighbors by at least a specified minimum distance. This results in a well-spaced and visually appealing pattern that avoids clustering or large gaps.

In creative coding and generative art Bridson’s algorithm is probably the most common approach to achieve a Poisson Disk Sampling—the algorithm works by first placing an initial random point and then attempts to iteratively place new points in the proximity of existing points in random directions, enforcing the minimum distance constraint. There’s many resources that cover the topic: an iconic one is Sighack’s write-up about implementing the algo in Processing, naturally the coding train’s also covered the topic, as well as Sebastian Lague.
Overall the algorithm is really potent in a procedural setting, either for the placement of things, or for using it as an underlying structure to create triangulations, and/or other kinds of grids. The caveat however, is that it relies on a spatial data-structure to remember the position of the already placed points and enforce the minimum distance requirement. It also isn’t really a true uniform distribution, but rather a kind of blue noise distribution.
True uniform point distributions on the other hand, might not be as visually pleasing, but are still quite useful in for procedural generation purposes. In a recent article, Boris Brave explores an approach geared towards that end, in a infinite setting, by using a Poisson Point Process—which turns out to be a techniques that hasn’t actually previously been documented before:

By subdividing the plane into square chunks, and then distributing points inside of the cells, the illusion of an infinite point distribution is made possible. The number of points in each cell is determined by a poisson distribution, where the index of the square chunk serves as a seed, in turn making it possible to remember what the random points in any given chunk are. Boris explains the maths behind this in the post and demonstrates that by hiding the underlying grid it makes it seem like a very organic distribution.
Other Cool Generative Things
- When this newsletter comes out then it'll already be to late to participate in this jam event—Proc Jam 2024 took place over the course of October, and somehow I completely missed it. But I still wanted to point it out as we may see some cool creations submitted to the event.
- In an article of his Matt Greer explains how he crammed a full featured recreation of Solitaire he programmed onto a Nintendo E-Reader—a Game Boy Advance peripheral that Nintendo released in 2002 and allows you to run mini games and other apps.
- Sergey Borovikov shares a codepen sketch on how to pack spheres such that they do not intersect when viewed on any axis—not sure how to describe other than this, check out the video he posted over on Twitter, self-explanatory when you see it. Jeff Clark pitches his own sketch in the replies, with a take on the idea where there additionally are shapes cut out of the packing area.
Tech & Web Dev
Should Masonry be Part of CSS Grid
Last week we saw the WebKit blog publish an update post on the CSS Masonry debate, in which Jen Simmons talks us through the current state of affairs asking for help to decide on the final syntax of CSS Masonry. She explains that the implementation has now been figured out, but what remains is whether or not Masonry should actually be integrated with the Grid spec or become its own layout mode.
This week CSS expert Ahmad Shadeed weighs in on the discussion with an insightful article that's as always chockfull with interactive examples:
 Ahmad Shadeed
Ahmad Shadeed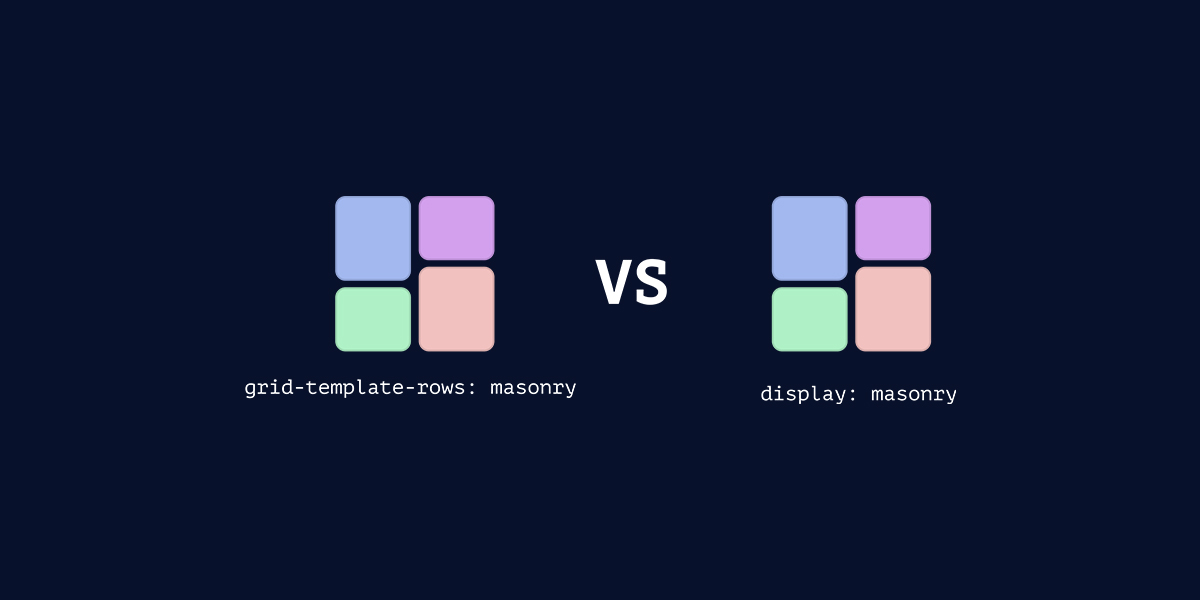
Shadeed believes that integrating masonry as part of the Grid spec is more practical than making it a separate layout module for a couple of reasons: having masonry as part of the grid spec would reduce code duplication and simplify progressive enhancement—considering that it will take a while for browsers to roll-out support for masonry, devs could simply fall back on the standard grid layout in browsers that do not yet support it yet. Otherwise you’d require separate styling ruels.
Shadeed also argues that masonry is essentially a form of a grid layout, so it doesn’t make sense to treat it as an entirely new module. This way it also becomes possible to dynamically switch between normal grid and masonry layouts based on conditions like viewport size or the number of items in the grid.
Jake Lazaroff’s Modern CSS Reset
I’ve mentioned CSS resets in a couple of issues at this point, but I never actually explained what it exactly is! A CSS reset is basically a set of CSS rules that eliminates the default styling applied by web browsers to HTML elements. Browsers usually have built-in styles for elements like margins, padding, and headings, and they often annoyingly vary between different browsers which can lead to inconsistencies your web designs. That’s why it makes sense to start with a clean slate and use a CSS reset as a baseline for styling purposes.
The first CSS reset was proposed by Eric Meyer in 2007. It gained widespread popularity as a practical solution for managing browser inconsistencies and became a staple in web developer toolkits. His reset was designed to address the significant inconsistencies in styling across browsers, that were prevalent at the time. Meyer’s reset removed all default margins, padding, and other stylistic properties from HTML elements, making cross-browser compatibility easier to manage, you can find it here if you’re interested in reading it:

While it’s become a bit of a tradition for web devs to postulate their own CSS resets, I’m bringing this up, because in last week’s issue I briefly pointed out Josh Comeau’s custom CSS reset, due to Josh making an update to it. This week, Jake Lazaroff (who you probably won’t remember making an appearance in issue #26 of the newsletter) published his own Modern CSS Reset that’s based in part on Comeau’s, with a couple of interesting modifications that he explains in a post over on his blog:

A special thing about Lazaroff’s reset is that it’s "classless", meaning that it applies styles only to elements without a class via the :not([class]) selector. This is to ensure base styles are only applied to unstyled elements, which makes it easier to customize elements with class-based styles. The goal here is to create a solid styling foundation while keeping the flexibility that makes it easy to override or extend styles without too much hassle.
Ghost CEO on Democratising Publishing
If you’ve been a reader of the newsletter for a while, you’ll have noticed that I’m somewhat of a Ghost fanboy—the open source software that powers the Gorilla Sun Blog. When I first migrated the blog from my own Jekyll+Github pages setup over to Ghost, I wrote a little bit about the reasons behind it in an article titled Goodbye Jekyll. At the time I did the switch relatively quickly, and while the pragmatic reasons for switching over to Ghost at the time are still valid—with time it became more and more clear that it is the ideal tool for my Blog.
It’s quite remarkable that Ghost is a self-sufficient non-profit building an open source tool in this day and age, when many other organizations have to rely on enshittifying their products to be profitable. In light of the wordpress drama, John O’Nolan, co-founder of Ghost, shares his thoughts on how they set themself apart from the others out there.

Our setup is pretty different to most, and while I certainly don't think we've got it all figured out — I think our model is especially relevant at this particular moment in time.
Other Cool Tech Things
- Chris McCully has been hard at work going down the solo dev route. He recently made a new write-up about some of the things he's made and shares his thoughts on product design as a solo dev.
- After purchasing a domain name for his side project, Bryan Braun discovers that this domain name is haunted and has a problematic backstory. He enumerates some steps to avoid getting spooked like he did.
AI Corner
Github Spark
Github Spark is a new AI platform that lets anyone build their own personalized micro apps—simply by describing them in natural language. Spark then also lets you run these apps in a hosted environment, that has access to the internet to make use of various APIs (as far as I understood from the demos they showcase), in addition to data storage, and LLM powered capabilities:

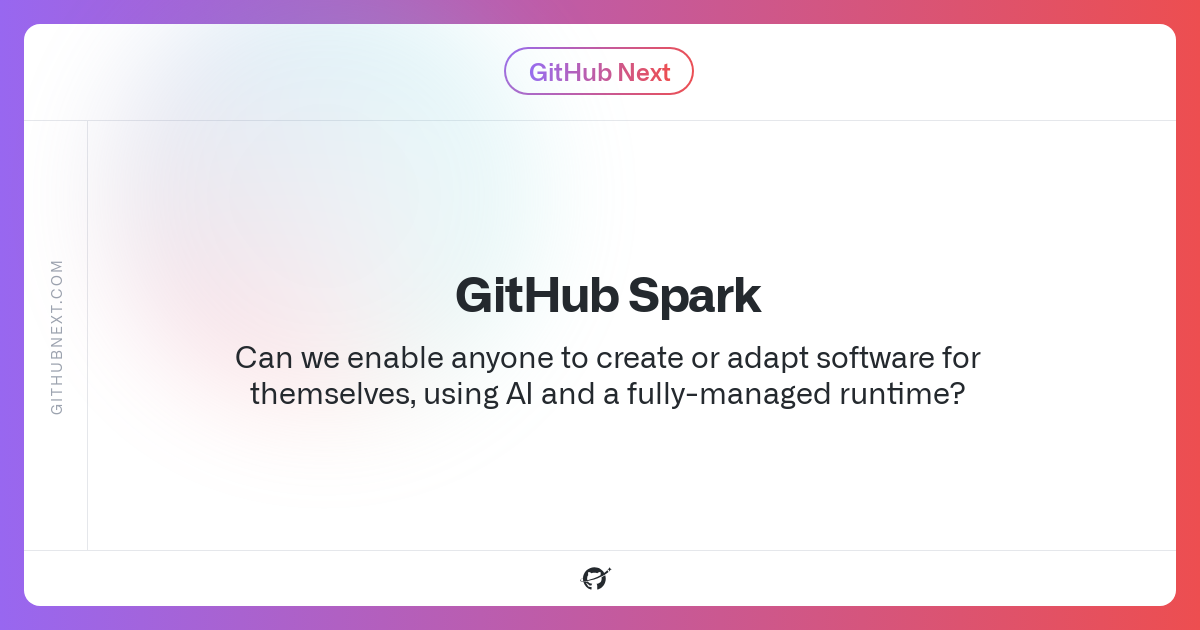
Right now Spark is only available via a waitlist, and it was a bit tricky to figure out how to actually get on the waitlist—here is the signup link if you're interested. Then you also have to head over to the Github Next (the folks developing Spark) discord server and drop your Github username in the “Let me Spark! Megathread!” thread of the Spark channel. I'm currently still waiting for access 🤷
Building things with Claude Artifacts
Last week we saw Claude roll out the analysis tool that now makes it possible to run code. Their artifacts feature however had already allowed for the generation of various types of content in a sidepanel next to the chat interface. Simon Willison wrote a big post about all of the single page web apps he’s built thus far with Claude Artifacts—if you need some inspiration while waiting for your access to Github Spark, check it out, some of them are actually quite useful:
Music for Coding
I can’t believe this track is 9 years old at this point—I remember listening to Alabama Shakes Sound & Color on repeat back when it came out, at a time I was still living with my parents in Lebanon. Back then I was really trying to write and play my own music, and the opening track of the album was a huge inspiration. How I discovered the track eludes me at this point, probably some new release aggregator site.
I’m not going to lie, even though it’s a cheerful track it’s a bit difficult listening to it again—lots of emotions thinking back to some of these simpler days of my life, and it’s also sad to read that the band went on an indefinite hiatus in 2018. Regardless however, Brittany Howard, the lead singer, has still to this day one of my favorite voices—do yourself a favor and listen to the entire Sound & Color album when you’ve got an hour to spare:
And that's it from me—hope you've enjoyed this week's curated assortment of genart and tech shenanigans!
Now that you find yourself at the end of the Newsletter, you might as well share it with some of your friends - word of mouth is till one of the best ways to support me! Otherwise come and say hi over on my socials - and since we've got also got a discord now, let me shamelessly plug it again here. Come join and say hi
If you've read this far, thanks a million! If you're still hungry for more generative art things, you can check out last week's issue of the newsletter here:
And a backlog of all previous issues can be found here:

Cheers, happy coding, and again, hope that you have a fantastic week! See you in the next one!
~ Gorilla Sun 🌸